
System Design: Distributed caching (Caching Part II)
Caching part II (We go deeper into caching, different types of caching and how it works)

🔹 A distributed cache is a system that pools together the random-access memory (RAM) of multiple networked computers into a single in-memory data store used as a data cache to provide fast access to data.
🔹 While most caches are traditionally in one physical server or hardware component, a distributed cache can grow beyond the memory limits of a single computer by linking together multiple computers.
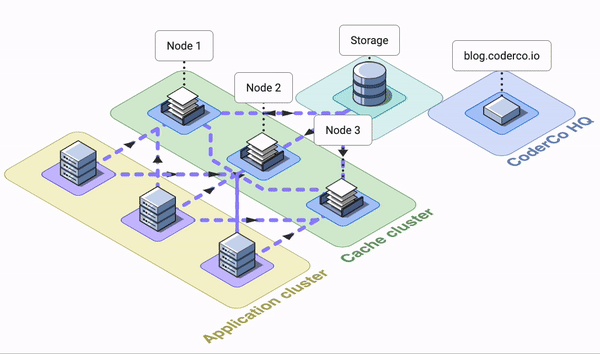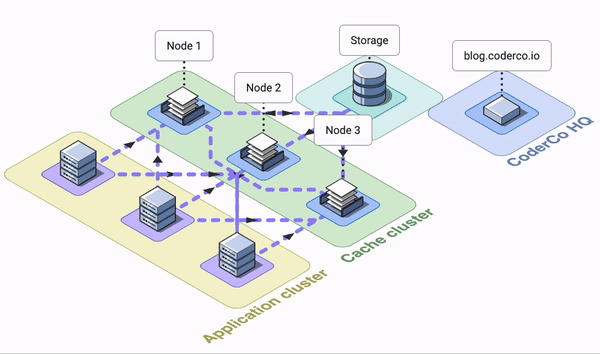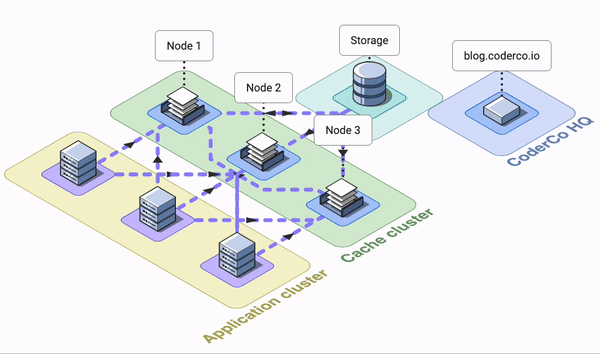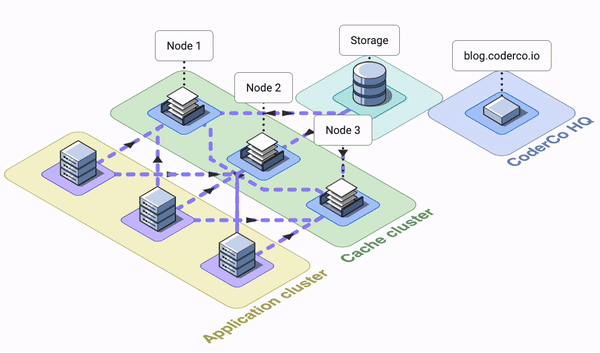
When cached data is distributed, the data is:
Consistent) across requests to multiple servers.
Able to survive server restarts and app deployments.
Does not use local memory.
What Are Popular Use Cases for a Distributed Cache?
Application acceleration
Decreasing network costs
Reducing impact of interruptions
Extreme scaling
Storing web session data
Distributed caching & distributed systems are the preferred choice for modern systems. Primarily due to the ability to scale & being available.
Google Cloud uses Memcache for caching data on its public cloud platform. Redis is used by internet giants for caching, NoSQL datastore & several other use cases.
In our next few post, we will go deeper into caching and discuss global caching, write-through caching, write-around caching, write-back caching, eviction policies, distributed caching and more!