
Linux Series EP2: Basic Linux Commands and Concepts: A Comprehensive Guide to Mastering Linux

Welcome back to our series on mastering Linux! We've already taken you through the intricate world of Linux file permissions in our previous post. Today, we're diving deeper into the Linux command line, exploring essential Linux commands and concepts that will help you navigate, manage, and comprehend the Linux environment effectively.
In this comprehensive guide, we'll cover not only the basics but also some additional topics that will augment your Linux command-line skills. Our journey will include navigating the Linux filesystem, managing files and directories, understanding processes and jobs, working with text editors, dealing with streams, pipes, redirects, and comprehending environment variables. We'll also touch upon the powerful world of regular expressions and the efficient use of command-line history and shortcuts. So, let's get started!

Table of Contents
Navigating the Linux Filesystem
Linux File and Directory Management
Understanding Linux Processes and Jobs
Using Text Editors: Vi/Vim, Nano, Emacs
Working with Streams, Pipes, and Redirects
Understanding Environment Variables
Introduction to Regular Expressions
Efficient Use of Command-Line History and Shortcuts
Conclusion
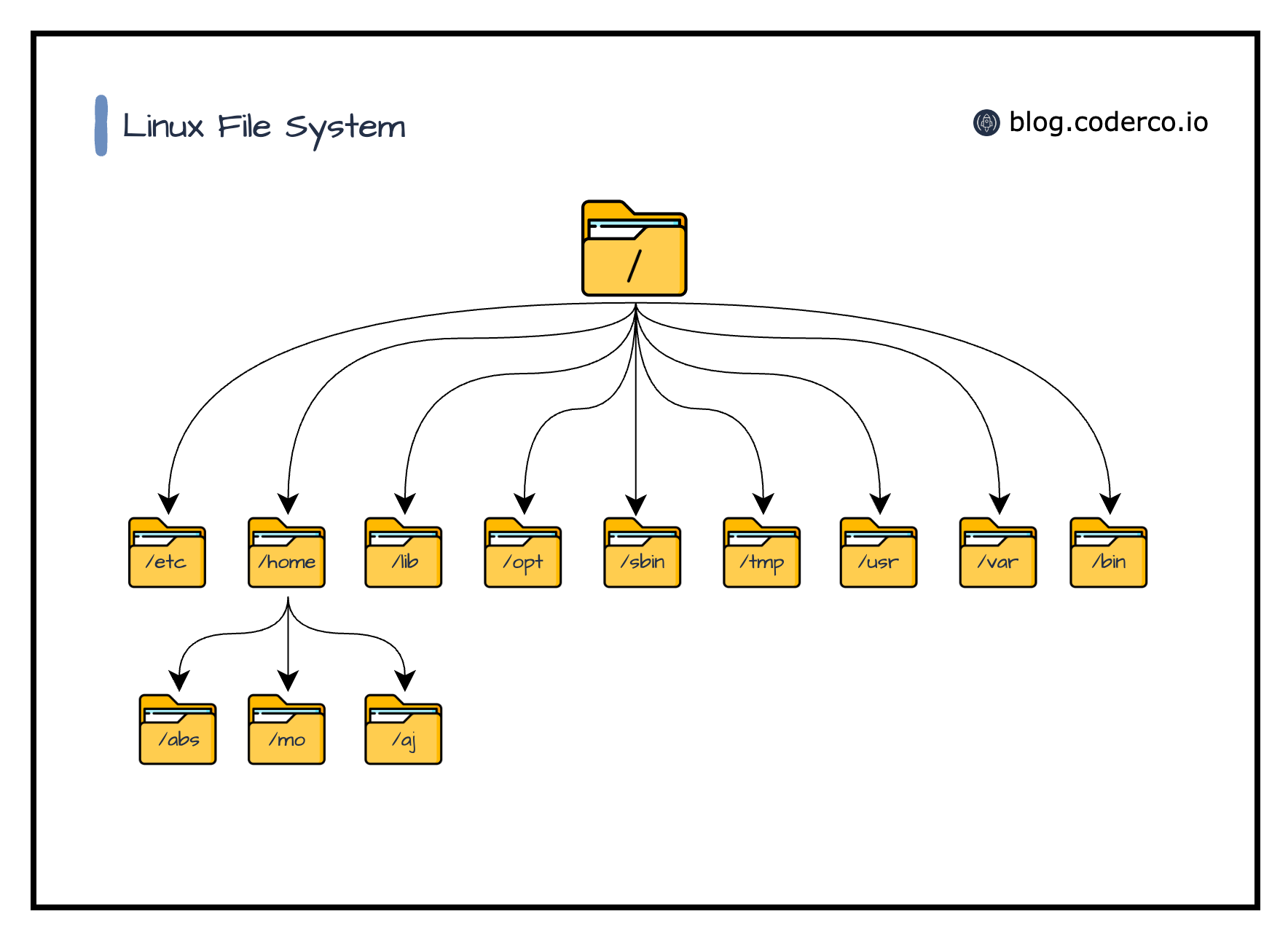
Navigating the Linux Filesystem
Every Linux user must master the art of navigating the filesystem. Remember, Linux employs a hierarchical directory structure. At the apex is the root directory, denoted as '/'. Every other directory branches out from the root, just like a tree.
Here are some basic commands for navigating this structure:
pwd: 'Print Working Directory'. It displays the current directory you're located in.cd: 'Change Directory'. This command allows you to move to a different directory. For example,cd /homewill take you to the 'home' directory.ls: 'List'. It lists the contents of a directory. By usingls -l, you get a long listing format that includes additional details such as permissions, number of links, owner, group, size, and time of last modification.
Think of these commands as your compass in the vast world of the Linux filesystem.
Linux File and Directory Management
Efficient file and directory management are key to being productive in Linux. Here are the key commands you should know:
mkdir: 'Make Directory'. It creates a new directory. For instance,mkdir newDirwill create a directory called 'newDir'.touch: This command is used to create a new empty file. For example,touch newFilewill create an empty file named 'newFile'.cp: 'Copy'. This command copies files or directories. For example,cp sourceFile destinationFilewill create a copy of 'sourceFile' named 'destinationFile'.mv: 'Move'. It can move files or directories, but it's also used to rename them. For example,mv oldName newNamewill rename the file 'oldName' to 'newName'.rm: 'Remove'. This command deletes files or directories. Be careful when using this command, especially with ther(recursive) option, as it deletes files and directories permanently.
To understand the structure and type of files, you can use the file command, which classifies a file's content. For instance, file myFile.txt will tell you that myFile.txt is a text file.
To search for files, use the find command. For instance, find /home -name myfile.txt will search for myfile.txt within the /home directory and its subdirectories.
Understanding Linux Processes and Jobs
A running program is termed a 'process' in Linux. Each process has a unique identification number or a process ID (PID). Here are some important commands:
ps(Process Status): Provides information about the currently running processes.toporhtop: These commands give a real-time, dynamic view of all running processes.bg(Background): This command resumes paused jobs and runs them in the background.fg(Foreground): This command brings a background job to the foreground.kill: This command terminates a process. For example,kill PIDwill terminate the process with the given PID.
To monitor the system's performance and resource usage, you can use the vmstat, iostat, and netstat commands. These tools give you insights into memory, CPU, IO, and network usage, respectively.
Using Text Editors: Vi/Vim, Nano, Emacs
Text editors are an integral part of any Linux setup. Let's get acquainted with three popular text editors: Vi/Vim, Nano, and Emacs. We'll also briefly touch on some more advanced editors like Sublime Text and Atom.
Vi/Vim
Vi (Visual) is a text editor that comes with most Unix-based systems. Vim (Vi Improved) is an extended version of Vi with additional features. Here are some basic Vim commands:
vim filename: Opens a file in Vim. If the file doesn't exist, it creates a new one.i: Switches to insert mode for typing text.:w: Saves changes.:q: Quits Vim. Use:q!to quit without saving changes.:wqorZZ: Saves changes and then quits Vim.
Nano
Nano is a user-friendly text editor perfect for beginners.
nano filename: Opens a file in Nano. If the file doesn't exist, it creates a new one.Ctrl+O: Saves changes.Ctrl+X: Exits Nano. If there are unsaved changes, it prompts you to save them before exiting.
Emacs
Emacs is a versatile working environment. It's much more than a text editor, providing tools like a mail client, news reader, calendar, and more.
emacs filename: Opens a file in Emacs. If the file doesn't exist, it creates a new one.Ctrl+X Ctrl+S: Saves changes.Ctrl+X Ctrl+C: Exits Emacs.
Sublime Text and Atom are other powerful editors with graphical interfaces, boasting features like multiple cursors, a minimap, highly customizable interface, etc. They don't come pre-installed with Linux distributions but can be easily downloaded and installed.

Working with Streams, Pipes, and Redirects
Linux uses the concepts of streams, pipes, and redirects to handle how programs read input and write output. Let's break these concepts down:
Streams are sources of data. There are three standard streams: stdin (standard input, usually from the keyboard), stdout (standard output, usually to the terminal), and stderr (standard error, for error messages, also usually to the terminal).
Pipes (
|) allow you to take the output from one command and use it as the input to another. For example,ls -l | grep txtwill list detailed directory contents and then search for lines containing 'txt'.Redirects are used to send the output from a command to a file instead of the terminal. The
>symbol sends stdout to a file, overwriting any existing content, while>>appends stdout to the file. The2>symbol redirects stderr. For example,ls -l > output.txtsaves the detailed directory listing to a file named 'output.txt'.
Understanding these concepts is crucial for creating complex command pipelines and managing program outputs effectively.

Understanding Environment Variables
Environment variables store information about the system environment and the shell session. Some common environment variables are $HOME, $PATH, $USER, and $SHELL. You can create your own environment variables using the export command. To see all environment variables, use the env or printenv command.
You can also create your own environment variables. For example, export VARNAME="value" creates a new environment variable named 'VARNAME' with the value 'value'. These custom variables are only available for the current session. To make them persistent, you need to add the export command to your shell's configuration file (like .bashrc or .bash_profile).

Introduction to Regular Expressions
Regular expressions, also known as regex or regexp, are a powerful tool for matching patterns in text. This capability can be extensively used in a variety of Linux commands, including grep, sed, awk, and many more. In fact, the practical applications of regex in Linux are virtually endless.
The Power of Regex
In the simplest terms, regular expressions are a sequence of characters that form a search pattern. This pattern can be used to match, locate, and manage text. Regular expressions can be simple, such as searching for a specific word, or they can be complex, like finding an email address within a text.
To truly appreciate the power of regex, let's dive deeper into its usage in several commonly used Linux commands.
Using Regex with grep
The grep command, which stands for 'Global Regular Expression Print,' is one of the most common commands used with regex. This command searches for a pattern in a file (or input from a pipeline) and prints the matching lines.
For example, the command grep 'tex*' file.txt will search for the word 'tex' followed by any characters in file.txt.
But regex offers so much more than just simple pattern matching. Let's examine some useful regex expressions that can be used with grep:
grep '^tex' file.txt: This command will match lines that start with 'tex'.grep 'tex$' file.txt: This command will match lines that end with 'tex'.grep '[Tt]ex' file.txt: This command will match lines that contain either 'Tex' or 'tex'.grep 't.x' file.txt: This command will match lines that contain 't', followed by any character, followed by 'x'.
Using Regex with sed
The sed command (stream editor) is another command where regex plays a significant role. It can perform a lot of functions on file data like searching, find and replace, insertion, and deletion.
For instance, you can use sed with regex to perform find and replace operations:
sed 's/tex/Test/' file.txt: This command will replace the first occurrence of 'tex' with 'Test' in each line.sed 's/tex/Test/g' file.txt: This command will replace all occurrences of 'tex' with 'Test'.
Using Regex with awk
awk is a scripting language used for manipulating data and generating reports. The awk command programming language requires no compiling, and allows the user to use variables, numeric functions, string functions, and logical operators.
awk uses regex for pattern matching. For instance, awk '/tex/ {print}' file.txt will print the lines from file.txt that match the pattern 'tex'.
Regex Special Characters and Sequences
Regular expressions use several special characters and sequences for matching patterns:
.: Matches any single character.``: Matches zero or more of the preceding character or group.
+: Matches one or more of the preceding character or group.?: Matches zero or one of the preceding character or group.^: Matches the beginning of a line.$: Matches the end of a line.[abc]: Matches any character enclosed in the square brackets.[^abc]: Matches any character not enclosed in the square brackets.{n}: Matches exactly 'n' consecutive instances of the preceding character or group.{n,m}: Matches between 'n' and 'm' instances of the preceding character or group.\\: Escapes the following character, allowing you to match special characters like **.**or ``.
For example:
a.bwill match 'acb', 'aab', 'adb', etc., but not 'ab' or 'aabb'.a*will match '', 'a', 'aa', 'aaa', etc.a+will match 'a', 'aa', 'aaa', etc., but not ''.a?will match '' and 'a', but not 'aa'.^abcwill match any line that starts with 'abc'.abc$will match any line that ends with 'abc'.[abc]will match any of 'a', 'b', or 'c'.[^abc]will match any character that is not 'a', 'b', or 'c'.a{3}will match 'aaa', but not 'aa' or 'aaaa'.a{2,4}will match 'aa', 'aaa', and 'aaaa', but not 'a' or 'aaaaa'.
Regular expressions can get complex, and mastering them requires practice. A good strategy is to start with simple patterns and gradually move on to more complex ones as you become more comfortable.
Regular expressions are an extremely powerful tool in Linux. While the learning curve might be steep, the benefits in terms of text processing capabilities are immense. Even learning the basics can dramatically increase your efficiency in handling and manipulating text in Linux. So take your time, practice, and before you know it, you'll be wielding regular expressions like a pro.

Efficient Use of Command-Line History and Shortcuts
Efficiency is key when you're working in a Linux environment. Here are some tips to boost your productivity:
Command-Line History: You can press the up and down arrow keys to cycle through previously executed commands. Also, you can use the
historycommand to display a list of previously executed commands.Searching Through History: Press
Ctrl+Rand start typing to search through the command history.Command-Line Shortcuts: There are numerous shortcuts that can save you time, such as
Ctrl+Cto terminate a command,Ctrl+Zto suspend a command,Ctrl+Ato go to the beginning of the line, andCtrl+Eto go to the end of the line.
Mastering these shortcuts can significantly improve your speed and efficiency when working with the Linux command line.

Conclusion
Mastering the Linux command line is an ongoing journey. The knowledge we've shared in this post will empower you to navigate and manipulate the Linux filesystem, understand processes and jobs, work with a variety of text editors, deal with streams, pipes, and redirects, and comprehend environment variables. Moreover, we've introduced you to the powerful world of regular expressions and shared some productivity tips for efficient use of command-line history and shortcuts.
Remember that Linux is an extremely powerful tool. As with any tool, it takes practice to become proficient. Don't hesitate to experiment with these commands and concepts. As you gain familiarity, you'll find that you're able to achieve more with less effort and in less time.
In our next blog post, we'll continue our exploration into the fascinating world of Linux. Stay tuned for more informative and engaging content!
Till then, keep learning, keep experimenting, and enjoy your journey through the exciting world of Linux!